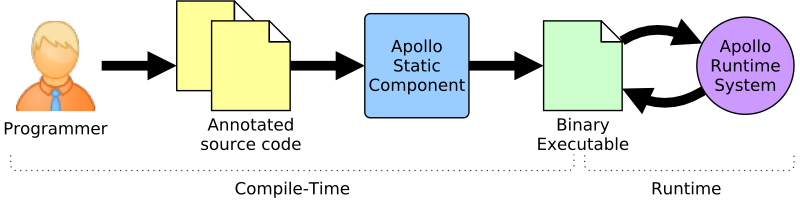
Overview
To use APOLLO, the programmer has to enclose the targeted loop nests using a dedicated #pragma directive.
Inside the #pragma any kind of loops are allowed, for-loops, while-loops, do-while-loops or goto-loops.
Please see APOLLO User Guide for more details.

At compile time, the programmer compiles his annotated source code with APOLLO. Then, the runtime system of APOLLO
orchestrates the execution and dynamically optimizes the code.
Execution by "Chunks"
To be reactive to changes of its behavior, APOLLO executes the target loop nest by chunks of iterations, switching
between code versions at each chunk. A chunk is a set of contiguous iterations of the outermost loop.
At the beginning of the execution of a loop, APOLLO profiles a few iterations inside a small chunk using the
instrumented version of the code. The next chunk can be executed using a different code version, as for example an
optimized version. In this way, the loop is executed as a succession of chunks. Between chunks, the control returns
to the runtime system. At this point, APOLLO is able to decide about the execution of the next chunk. In our approach,
the chunks are executed sequentially, but iterations inside a chunk may be executed in parallel.
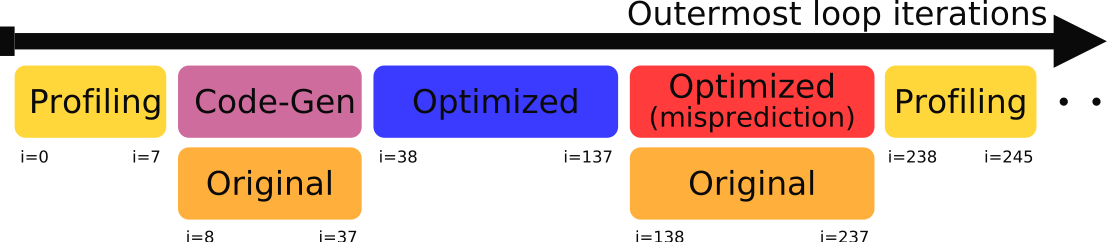
The behavior of the current chunk and the result of its execution determine the next chunk.
- At the beginning of the execution of a loop nest, or after completion of a chunk running the original version of the code, a profiling chunk is launched to capture the runtime code behavior. Once the profiled execution finishes, APOLLO moves to the code-generation phase.
- During the code generation phase, a prediction model is build and a transformation is selected. From the selected transformation, optimized binary code is generated using the LLVM Just-In-Time compiler. If successful, APOLLO is ready to execute optimized code; if not, the execution continues using the original version of the code. In parallel to this, a background thread executes the original version of the code, in order to mask, at least partially, the related time overhead.
- Always before executing optimized code, APOLLO performs a preventive backup of the predicted write memory areas (thanks to the prediction model). Once the backup has been performed, APOLLO executes the optimized code. Optimized chunks are executed until a misspeculation occurs. Iterations inside an optimized chunk are most often run in parallel.
- When a misspeculation is detected, a rollback is performed to recover the memory state prior to the execution of the faulty chunk.
- The same chunk is re-executed using the original version of the code, which is obviously semantically correct.
Results
The set of benchmarks has been built from a collection of benchmark suites, such
that the selected codes include a main kernel loop nest and highlight APOLLO's capabilities:
SOR from the Scimark suite;
Backprop and Needle from the
Rodinia suite;
DMatmat, ISPMatmat, Spmatmat and
Pcg from the SPARK00 suite of irregular
codes; and Mri-q from the Parboil suite.
In table below, we identify the characteristics for each benchmark that make them impossible to parallelize at compile-time.
| Benchmark | Has indirections | Has pointers | Unpredictable bounds | Unpredictable scalars |
|---|---|---|---|---|
| Mri-q | ✓ | |||
| Needle | ✓ | |||
| SOR | ✓ | ✓ | ||
| Backprop | ✓ | ✓ | ||
| PCG | ✓ | ✓ | ✓ | ✓ |
| DMatmat | ✓ | ✓ | ||
| ISPMatmat | ✓ | ✓ | ✓ | ✓ |
| SPMatmat | ✓ | ✓ | ✓ | ✓ |
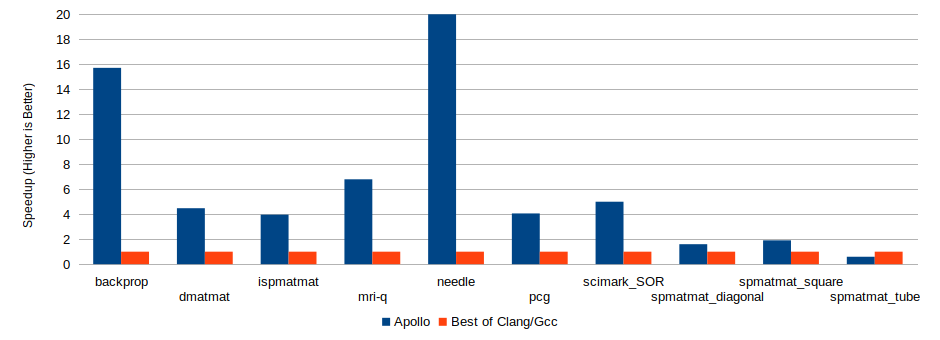
The benchmark codes were run on two different machines:
- Lemans, a general-purpose multi-core server, with two AMD Opteron 6172 processors of 12 cores each (24 in total).
- Armonique, an embedded system multi-core chip, with one ARM Cortex A53 64-bit processor of 8 cores.
We compared the original code optimized with APOLLO (version 1.0) against the best outcome obtained from the original code compiled using either LLVM/Clang (version 3.8) or GCC (version 5.3.1) with optimization level 3 (-O3).
AMD Opteron 6172, 2X12-core
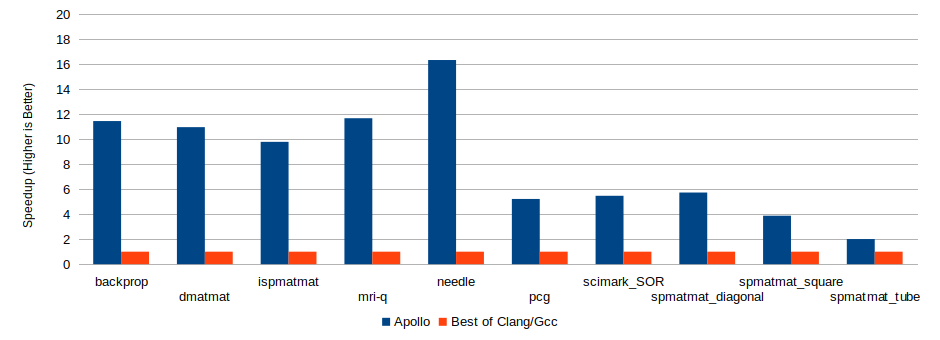
ARM Cortex A53, 8-core